1次関数から試してみます。最小二乗法は、誤差を2乗した合計が小さくなるようにすることで、最もらしい関数を発見する方法です。1次関数でデータを10個つくって、作り出した関数を知らない前提で、機械に関数を発見してもらいます。
1次関数でやってみる
1次関数は下記でやってみます。 y = 3x * 5
トレーニングセット作成
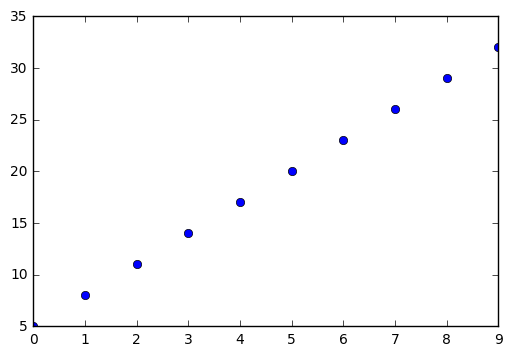
データを10個つくります。xは、0,1,2,3,4,5,6,7,8,9です。Pythonでつくります。
data_set = [] [data_set.append(3 * x + 5) for x in range(10)] print data_set
[5, 8, 11, 14, 17, 20, 23, 26, 29, 32]
これはグラフにすると下記になります。
import matplotlib.pyplot as plt plt.plot(data_set, 'o') plt.show()
TensorFlowでやってみる
モデルは、1次関数とします。パラメタは2つあります。誤差関数は、二乗誤差を使います。TensorFlowでやってみます。
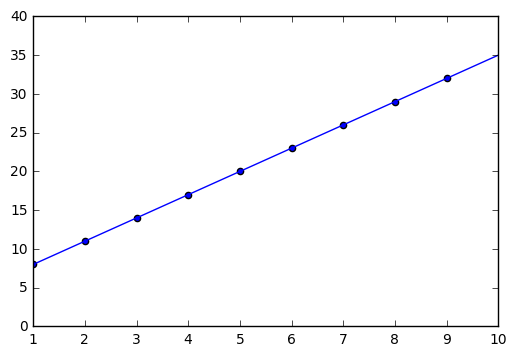
import tensorflow as tf x = tf.placeholder(tf.float32, [None, 2]) w = tf.Variable(tf.zeros([2, 1])) y = tf.matmul(x, w) t = tf.placeholder(tf.float32, [None, 1]) loss = tf.reduce_sum(tf.square(y - t)) train_step = tf.train.AdamOptimizer().minimize(loss) sess = tf.Session() sess.run(tf.initialize_all_variables()) train_t = np.array(data_set); train_t = train_t.reshape([10, 1]) train_x = np.zeros([10, 2]) for row in range(10): for col in range(2): train_x[row][col] = row**col i = 0 for _ in range(100000): i += 1 sess.run(train_step, feed_dict={x:train_x, t:train_t}) if i % 10000 == 0: loss_val = sess.run(loss, feed_dict={x:train_x, t:train_t}) print ('Step: %d, Loss: %f' % (i, loss_val)) w_val = sess.run(w) print w_val def predict(x): result = 0.0 for n in range(0, 2): result += w_val[n][0] * x**n return result fig = plt.figure() subplot = fig.add_subplot(1, 1, 1) subplot.set_xlim(1, 10) subplot.scatter(range(10), train_t) linex = np.linspace(1, 10, 100) liney = predict(linex) subplot.plot(linex, liney) plt.show()
Step: 10000, Loss: 0.556078 Step: 20000, Loss: 0.000000 Step: 30000, Loss: 0.000000 Step: 40000, Loss: 0.000000 Step: 50000, Loss: 0.000000 Step: 60000, Loss: 0.000000 Step: 70000, Loss: 0.000000 Step: 80000, Loss: 0.000000 Step: 90000, Loss: 0.000000 Step: 100000, Loss: 0.000000 [[ 5.] [ 3.]]
1000刻みでLoss値を見てみる
20000回ですでに完璧に誤差がなくなっておりまして、きちんと正しい一次関数を発見しました。せっかくなので、1000刻みで見てみようと思います。
Step: 1000, Loss: 2144.477539 [[ 0.93216914] [ 0.93001837]] Step: 2000, Loss: 946.874451 [[ 1.73305488] [ 1.72308087]] Step: 3000, Loss: 324.689636 [[ 2.4027319 ] [ 2.37532687]] Step: 4000, Loss: 74.941284 [[ 2.92346025] [ 2.85973501]] Step: 5000, Loss: 13.527188 [[ 3.27773309] [ 3.14026999]] Step: 6000, Loss: 6.525241 [[ 3.50095201] [ 3.2282424 ]] Step: 7000, Loss: 4.923757 [[ 3.69913244] [ 3.2147882 ]] Step: 8000, Loss: 3.215882 [[ 3.94896293] [ 3.17392874]] Step: 9000, Loss: 1.630160 [[ 4.25151825] [ 3.1236279 ]] Step: 10000, Loss: 0.556078 [[ 4.56274843] [ 3.07208133]] Step: 11000, Loss: 0.099951 [[ 4.81459618] [ 3.03052568]] Step: 12000, Loss: 0.006101 [[ 4.95419312] [ 3.00753903]] Step: 13000, Loss: 0.000059 [[ 4.9954896 ] [ 3.00074267]] Step: 14000, Loss: 0.000000 [[ 4.99989605] [ 3.00001764]] Step: 15000, Loss: 0.000000 [[ 4.99996567] [ 3.00000596]] Step: 16000, Loss: 0.000000 [[ 4.9999795 ] [ 3.00000358]] Step: 17000, Loss: 0.000000 [[ 4.9999876 ] [ 3.00000215]] Step: 18000, Loss: 0.000000 [[ 4.99999428] [ 3.00000095]] Step: 19000, Loss: 0.000000 [[ 4.99999619] [ 3.00000072]] Step: 20000, Loss: 0.000000 [[ 4.99999857] [ 3.00000024]]
頭よくなっていく過程が分かります。しかし、1次関数かどうかは実際には分からないので、1次~10次までを確認して、一番いい感じのやつを発見するようなプログラムにするといいのではないかと思いました。あと、トレーニングセットとテストセットとかいうらしいですが、最初の学習データとは別のテストデータも必要になります。理由は過学習してしまう可能性があるからです。例えば10個のデータであれば9次関数をつくると確実に10個のデータを再現できる関数になります。しかしこれは過学習しており、11個目のデータがあったときに全然めちゃくちゃになってしまいます。
誤差つきの4次関数でやってみる
では次に4次関数でやってみます。また、実際のデータっぽく誤差をいれてみます。ソースコードきたないですが、実験なのでお許しください。
param_cntは、モデル式のパラメタの最大数です。11と入れると、10次関数まで調べます。3だと2次関数まで調べます。do_cntは、学習回数です。chk_cntは、何回ごとにloss値を出力させるか、です。4次関数にnp.random.normalで正規分布の誤差をいれています。平均0で、標準偏差3の正規分布の誤差ということになるそうです。
import numpy as np import matplotlib.pyplot as plt import tensorflow as tf param_cnt = 11 do_cnt = 20000 chk_cnt = 5000 data_set = [] x_list = np.arange(-5, 5, 0.5) [data_set.append(0.5 * x**4 + 0.9 * x**3 + 0.5 * x**2 + x + 5 + np.random.normal(0, 3)) for x in x_list] #[data_set.append(0.5 * x**4 + 0.9 * x**3 + 0.5 * x**2 + x + 5) for x in x_list] #[data_set.append(3 * x + 5) for x in x_list] data_cnt = len(data_set) def multi(param_cnt): step = 0 loss = 0.0 w = [] p_cnt = 0 for i in range(2, param_cnt + 1): result = ml(i) if i == 2 or loss > result['loss']: step = result['step'] loss = result['loss'] w = result['w'] p_cnt = i print str(p_cnt - 1) + '次関数' print w return {'param_cnt': param_cnt, 'w': w, 'step': step , 'loss': loss} def predict(x, w_list): result = 0.0 for i, w in enumerate(w_list): result += w[0] * x**i return result def plt_show(w): y = predict(x_list, w) plt.plot(x_list, y) plt.plot(x_list, data_set, 'o') plt.show() def ml(param_cnt): print str(param_cnt - 1) + '次関数:' x = tf.placeholder(tf.float32, [None, param_cnt]) w = tf.Variable(tf.zeros([param_cnt, 1])) y = tf.matmul(x, w) t = tf.placeholder(tf.float32, [None, 1]) loss = tf.reduce_sum(tf.square(y - t)) train_step = tf.train.AdamOptimizer().minimize(loss) sess = tf.Session() sess.run(tf.initialize_all_variables()) train_t = np.array(data_set); train_t = train_t.reshape([data_cnt, 1]) train_x = np.zeros([data_cnt, param_cnt]) for row, n in enumerate(x_list.tolist()): for col in range(param_cnt): train_x[row][col] = n**col i = 0 min_loss = 0.0 step = 0 w_fix = [] for _ in range(do_cnt): i += 1 sess.run(train_step, feed_dict={x:train_x, t:train_t}) if i % chk_cnt == 0: loss_val = sess.run(loss, feed_dict={x:train_x, t:train_t}) w_val = sess.run(w) print ('Step: %d, Loss: %f' % (i, loss_val)) print w_val if(i == chk_cnt or min_loss > loss_val): step = i min_loss = loss_val w_fix = w_val return {'step': step, 'loss': min_loss, 'w': w_fix.tolist()} result = multi(param_cnt) #result = ml(param_cnt) plt_show(result['w'])
1次関数: Step: 5000, Loss: 215542.093750 [[ 4.95924044] [ 3.95200872]] Step: 10000, Loss: 203412.828125 [[ 9.88683128] [ 5.01568365]] Step: 15000, Loss: 192418.406250 [[ 14.8010807] [ 5.1672349]] Step: 20000, Loss: 182398.625000 [[ 19.70719528] [ 5.31404638]] 2次関数: Step: 5000, Loss: 68691.289062 [[ 4.37834597] [ 4.78828716] [ 4.51071978]] Step: 10000, Loss: 19349.113281 [[ 6.14278746] [ 9.20509338] [ 8.05002975]] Step: 15000, Loss: 14812.129883 [[ 0.76773846] [ 11.64998531] [ 9.2823782 ]] Step: 20000, Loss: 13354.574219 [[ -4.00546932] [ 11.78009605] [ 9.61374664]] 3次関数: Step: 5000, Loss: 67975.859375 [[ 4.38982058] [ 4.47143745] [ 4.52593517] [ 0.12835987]] Step: 10000, Loss: 18511.107422 [[ 6.25019884] [ 7.83472824] [ 8.12683201] [ 0.19194219]] Step: 15000, Loss: 14246.777344 [[ 0.85353625] [ 7.43424273] [ 9.42072201] [ 0.286881 ]] Step: 20000, Loss: 12680.401367 [[-3.94125748] [ 7.13879824] [ 9.76669121] [ 0.31357336]] 4次関数: Step: 5000, Loss: 116.987244 [[ 1.75886464] [ 0.82387865] [ 0.73796004] [ 0.90688848] [ 0.49740523]] Step: 10000, Loss: 21.997097 [[ 4.06656361] [ 1.1654942 ] [ 0.78540492] [ 0.88064975] [ 0.48745832]] Step: 15000, Loss: 16.351856 [[ 5.03755283] [ 1.10082293] [ 0.56437576] [ 0.88661832] [ 0.49617034]] Step: 20000, Loss: 16.351896 [[ 5.03769445] [ 1.10081434] [ 0.56434351] [ 0.8866201 ] [ 0.4961707 ]] 5次関数: Step: 5000, Loss: 119.090012 [[ 1.74797881e+00] [ 1.08122551e+00] [ 7.19700754e-01] [ 8.64906728e-01] [ 4.98723030e-01] [ 1.43910421e-03]] Step: 10000, Loss: 22.015015 [[ 4.06811666e+00] [ 1.07059586e+00] [ 7.93005526e-01] [ 8.97920549e-01] [ 4.86883730e-01] [ -6.27588655e-04]] Step: 15000, Loss: 16.261492 [[ 5.05882359e+00] [ 1.18433976e+00] [ 5.52112699e-01] [ 8.70472431e-01] [ 4.96929288e-01] [ 5.98916959e-04]] Step: 20000, Loss: 16.260433 [[ 5.05913115e+00] [ 1.18449724e+00] [ 5.52029669e-01] [ 8.70452166e-01] [ 4.96929288e-01] [ 6.06292742e-04]] 6次関数: Step: 5000, Loss: 53.637337 [[ 2.38433266e+00] [ 1.57903039e+00] [ 1.11886275e+00] [ 8.11793208e-01] [ 4.61589992e-01] [ 2.50088377e-03] [ 6.97513111e-04]] Step: 10000, Loss: 18.967039 [[ 4.32346010e+00] [ 1.32767844e+00] [ 9.70935225e-01] [ 8.36955488e-01] [ 4.52258199e-01] [ 2.08282284e-03] [ 1.26212556e-03]] Step: 15000, Loss: 16.296326 [[ 4.93837500e+00] [ 1.22425616e+00] [ 6.37905777e-01] [ 8.61216605e-01] [ 4.87015426e-01] [ 1.01356197e-03] [ 2.91907112e-04]] Step: 20000, Loss: 16.242428 [[ 5.01489973e+00] [ 1.20275176e+00] [ 5.88385046e-01] [ 8.65994036e-01] [ 4.92458344e-01] [ 8.08077923e-04] [ 1.36406394e-04]] 7次関数: Step: 5000, Loss: 89.665520 [[ 2.32143140e+00] [ 1.53826487e+00] [ 1.07825494e+00] [ 6.85688794e-01] [ 4.76195693e-01] [ 1.93343945e-02] [ -2.91685792e-05] [ -4.58549795e-04]] Step: 10000, Loss: 20.448008 [[ 4.28025007e+00] [ 1.64763474e+00] [ 1.00642896e+00] [ 7.50945508e-01] [ 4.48578656e-01] [ 8.27948842e-03] [ 1.35072204e-03] [ -1.31144610e-04]] Step: 15000, Loss: 17.463367 [[ 4.70802307e+00] [ 1.52105701e+00] [ 7.85070360e-01] [ 7.84407139e-01] [ 4.71286625e-01] [ 6.25595590e-03] [ 7.26952916e-04] [ -1.02008424e-04]] Step: 20000, Loss: 16.643923 [[ 4.87714958e+00] [ 1.42680812e+00] [ 6.72681332e-01] [ 8.05022180e-01] [ 4.83814031e-01] [ 5.21623669e-03] [ 3.65617452e-04] [ -9.24795459e-05]] 8次関数: Step: 5000, Loss: 131.079254 [[ 2.88559628e+00] [ 1.24204707e+00] [ 1.10422873e+00] [ 3.27726752e-01] [ 2.82681823e-01] [ 7.58507699e-02] [ 2.27710828e-02] [ -2.43731448e-03] [ -6.57664554e-04]] Step: 10000, Loss: 28.809479 [[ 4.29814291e+00] [ 2.01223731e+00] [ 1.31598830e+00] [ 3.96377593e-01] [ 3.03849131e-01] [ 5.24885505e-02] [ 1.58709679e-02] [ -1.51652610e-03] [ -4.02022008e-04]] Step: 15000, Loss: 347.819122 [[ 4.51162624e+00] [ 2.24438071e+00] [ 1.33831608e+00] [ 4.33518320e-01] [ 3.07972670e-01] [ 4.39823009e-02] [ 1.46628506e-02] [ -1.24611927e-03] [ -3.21475236e-04]] Step: 20000, Loss: 22.053818 [[ 4.52574492e+00] [ 2.27882338e+00] [ 1.34143877e+00] [ 4.55701292e-01] [ 3.11556101e-01] [ 4.05396298e-02] [ 1.40584493e-02] [ -1.09993061e-03] [ -3.34182230e-04]] 9次関数: Step: 5000, Loss: 5552.634766 [[ 2.33792377e+00] [ 7.79350579e-01] [ 6.53970003e-01] [ 2.03688577e-01] [ 1.83490813e-01] [ 4.28588130e-02] [ 4.29749712e-02] [ 3.35324835e-03] [ -1.39146764e-03] [ -1.60500247e-04]] Step: 10000, Loss: 194.072403 [[ 4.08490229e+00] [ 1.23215306e+00] [ 9.06385481e-01] [ 2.92194337e-01] [ 2.03426927e-01] [ 5.21436632e-02] [ 3.42375599e-02] [ 7.02911580e-04] [ -1.01602043e-03] [ -9.27555739e-05]] Step: 15000, Loss: 115.676407 [[ 4.94008017e+00] [ 1.50322270e+00] [ 1.05627847e+00] [ 3.42464149e-01] [ 2.18068600e-01] [ 5.66791482e-02] [ 2.89440639e-02] [ -7.18827709e-04] [ -8.12099199e-04] [ -3.92189686e-05]] Step: 20000, Loss: 57.366673 [[ 5.27173281e+00] [ 1.66980028e+00] [ 1.15057874e+00] [ 3.71282339e-01] [ 2.29773715e-01] [ 5.85983880e-02] [ 2.56161764e-02] [ -1.47335778e-03] [ -6.85952662e-04] [ -1.29779210e-05]] 10次関数: Step: 5000, Loss: 2263.479736 [[ 1.01189530e+00] [ 2.97042310e-01] [ 2.68756747e-01] [ 8.43940526e-02] [ 8.09634402e-02] [ 2.73650903e-02] [ 2.04845257e-02] [ 8.72469600e-03] [ 2.38272268e-03] [ -4.05140279e-04] [ -1.13759939e-04]] Step: 10000, Loss: 1553.578125 [[ 1.83733785e+00] [ 4.96752053e-01] [ 4.51538861e-01] [ 1.11230105e-01] [ 1.25275597e-01] [ 2.73409784e-02] [ 2.71124728e-02] [ 7.42600206e-03] [ 1.07120932e-03] [ -3.40760889e-04] [ -7.36084112e-05]] Step: 15000, Loss: 860.454346 [[ 2.45131707e+00] [ 7.04376996e-01] [ 5.79612136e-01] [ 1.44563615e-01] [ 1.54916033e-01] [ 2.92531345e-02] [ 3.12672704e-02] [ 6.10585557e-03] [ 1.98022972e-04] [ -2.84481910e-04] [ -4.43308709e-05]] Step: 20000, Loss: 585.964172 [[ 2.91786623e+00] [ 9.03335571e-01] [ 6.71693385e-01] [ 1.79319546e-01] [ 1.75147504e-01] [ 3.20737772e-02] [ 3.38761806e-02] [ 4.85530496e-03] [ -3.96082381e-04] [ -2.33632789e-04] [ -2.46588024e-05]] 6次関数 [[5.014899730682373], [1.2027517557144165], [0.5883850455284119], [0.8659940361976624], [0.4924583435058594], [0.0008080779225565493], [0.00013640639372169971]]

6次関数が選ばれました。本当は違うんだけど、グラフは点をしっかり大体通ってます。テストデータで確かめると、4次関数の方がいいってなるのかもしれない。今度はテストデータで確かめたり色々してみようと思います。