BTCFXの約定データで強化学習してみる
BTCFXの1日分の約定データ(1分足データ)をもとに、取引方法を学習させてみたいと思います。Open AI GymのEnvというのを自作することで、学習環境を自作することができます。 Open AI Gymが用意してくれているEnvは、env = gym.make('CartPole-v0')といった形で簡単に利用できますが、これと同じように自作のEnvも簡単に読み込めるようにすることができます。下記のようなディレクトリ構造にします。
envのディレクトリ構造
bf├── __init__.py└── env.pyinit.py
init.pyは下記のようにします。
from gym.envs.registration import register
register( id='bf-v0', entry_point='bf.env:BfEnv')env.py
env.pyに、自作環境を書きます。約定データのjsonファイルを読み込み、学習環境の状態や、1ステップ毎にあげる報酬の設定などをします。
import mathimport gymimport numpy as npimport gym.spacesimport jsonfrom random import randint
class BfEnv(gym.Env): def __init__(self): super(BfEnv, self).__init__() self.action_space = gym.spaces.Discrete(3) self.observation_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(300, 5), dtype=np.float32) self.executions = self._readJsonFile() self._reset()
def _readJsonFile(self): with open('executions_0213.json') as f: return np.array(json.load(f))
def _resetIdx(self): max = self.executions.shape[0] - 300 + 1 # 300は5分のこと。5分分回して評価する min = 300 # 5分前のデータをobservationとして使う self.idx = randint(min, max) self.startIdx = self.idx self.endIdx = self.idx + 300 - 1
def _printResetState(self): print('startIdx: ', self.startIdx, 'endIdx: ', self.endIdx)
def _printState(self, reward): print('nowIdx: ', self.idx, 'reward: ', reward, 'done: ', self.done)
def _nextIdx(self): self.idx += 5
def _reset(self): self._resetIdx() self.done = False self.positions = [] self.orders = [] self._observe() # self._printResetState() self.steps = 0 return self.observation
def _observe(self): start = self.idx - 300 executions = self.executions[start:self.idx] observation = [exe[0:5] for exe in executions] self.observation = np.array(observation)
def _step(self, action): if action == 0: # hold pass elif action == 1: # buy self.orders.append([self.idx, 'BUY', self.executions[self.idx][5]]) elif action == 2: # sell self.orders.append([self.idx, 'SELL', self.executions[self.idx][5]])
self._nextIdx() self._checkOrderTimeLimit() reward = self._checkPosition() self.done = self.idx >= self.endIdx self._observe() # self._printState(reward) return self.observation, reward, self.done, {}
def _checkOrderTimeLimit(self): self.orders = [order for order in self.orders if self.idx < order[0] + 59]
def _checkPosition(self): executed = [] noExecuted = [] for order in self.orders: for exe in self.executions[self.idx - 5: self.idx]: if exe[6] <= order[2] <= exe[7]: executed.append(order) break noExecuted.append(order) self.orders = noExecuted reward = 0 for exe in executed: isPosi = len(self.positions) > 0 if isPosi: side = self.positions[0][1] if exe[1] == side: self.positions.append(exe) #ポジ持ちすぎチェック if len(self.positions) > 10: reward += self._lossCut() else: #ポジ解除処理 reward += self._posiFin(exe) else: self.positions.append(exe) return reward
def _posiFin(self, exe): posi = self.positions.pop(0) side = posi[1] price = posi[2] nowPrice = exe[2] if (side == 'BUY'): return nowPrice - price else: return price - nowPrice
def _lossCut(self): totalPrice = 0 for posi in self.positions: totalPrice += posi[2] avePrice = math.floor(totalPrice / len(self.positions)) side = self.positions[0][1] if (side == 'BUY'): nowPrice = self.executions[self.idx][6] reward = nowPrice - avePrice else: nowPrice = self.executions[self.idx][7] reward = avePrice - nowPrice reward -= math.floor(nowPrice * 0.05 / 100) #0.05% self.positions = [] return reward
def _render(self, mode='human', close=False): pass
def _close(self): pass
def _seed(self, seed=None): passbf.py
環境を作ったら、それを読み込んで学習を実行します。学習実行コードが下記です。といっても、どっかのサイトからぱくったもののほぼそのままです。Open AI Gymのお勉強記事の多くがこのコードで、kerasの本家サイトのサンプルのようです。
import gymfrom keras.layers import Dense, Activation, Flattenfrom keras.models import Sequentialfrom keras.optimizers import Adamfrom rl.agents.dqn import DQNAgentfrom rl.memory import SequentialMemoryfrom rl.policy import EpsGreedyQPolicyimport bf
ENV_NAME = 'bf-v0'env = gym.make(ENV_NAME)nb_actions = env.action_space.nprint(nb_actions)
# Next, we build a very simple model.model = Sequential()model.add(Flatten(input_shape=(1,) + env.observation_space.shape))model.add(Dense(32))model.add(Activation('relu'))model.add(Dense(32))model.add(Activation('relu'))model.add(Dense(32))model.add(Activation('relu'))model.add(Dense(nb_actions))model.add(Activation('linear'))print(model.summary())
# Finally, we configure and compile our agent. You can use every built-in Keras optimizer and# even the metrics!memory = SequentialMemory(limit=80000, window_length=1)policy = EpsGreedyQPolicy(eps=0.003)dqn = DQNAgent( model=model, nb_actions=nb_actions, gamma=0.99, memory=memory, enable_double_dqn=True, enable_dueling_network=False, nb_steps_warmup=3, target_model_update=1e-2, policy=policy)dqn.compile(Adam(lr=1e-3), metrics=['mae'])
# Okay, now it's time to learn something! We visualize the training here for show, but this# slows down training quite a lot. You can always safely abort the training prematurely using# Ctrl + C.dqn.fit(env, nb_steps=1000000, visualize=False, verbose=2)
# After training is done, we save the final weights.dqn.save_weights('dqn_{}_weights.h5f'.format(ENV_NAME), overwrite=True)
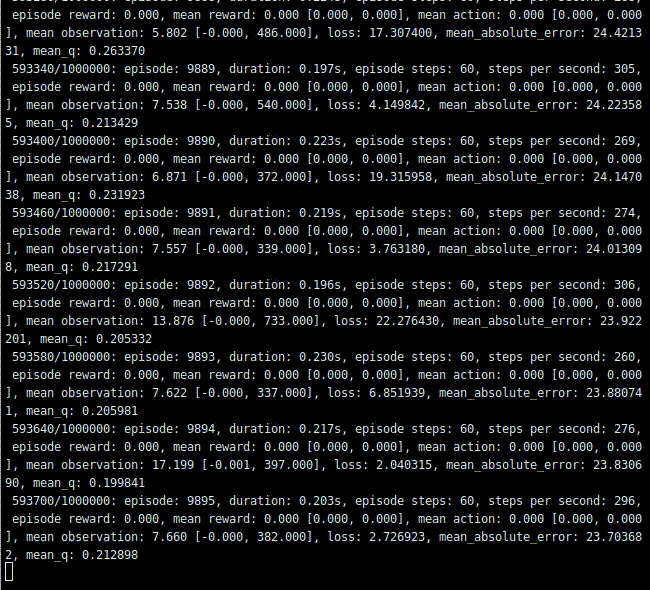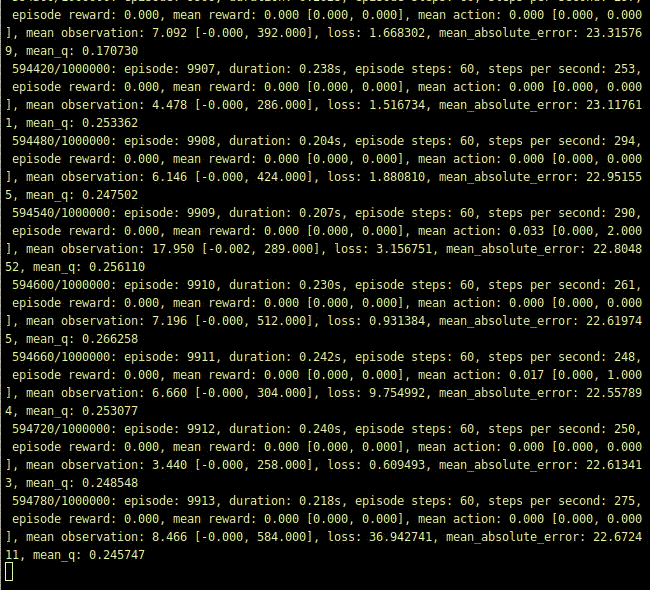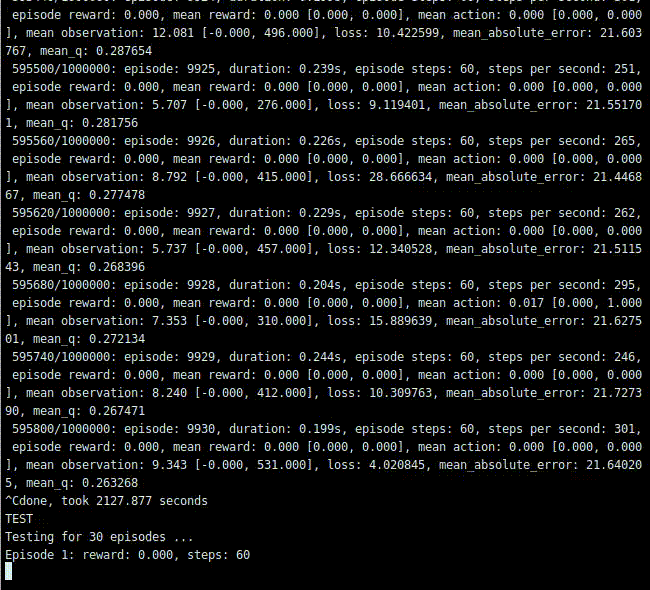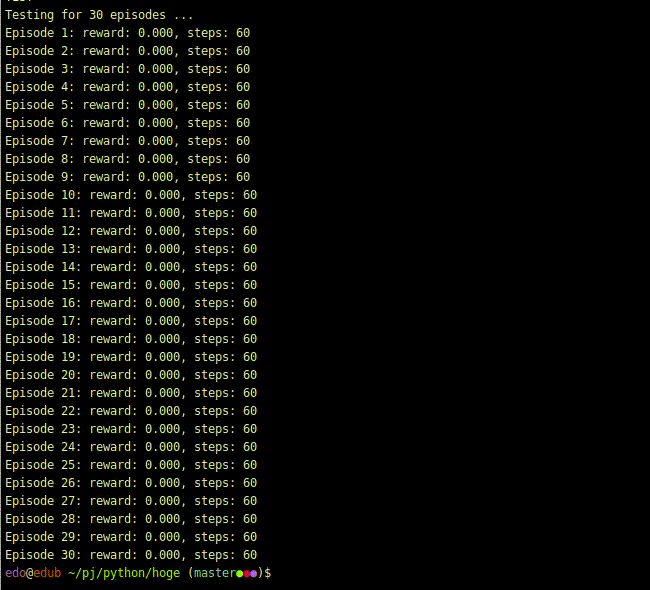
# Finally, evaluate our algorithm for 5 episodes.print('TEST')dqn.test(env, nb_episodes=30, visualize=False)実行結果
取引をしないことを学びました。