BTCFXの約定データで強化学習してみる (2)
下記で、Open AI Gymを使って、BTCFXの約定データをもとに強化学習するコードを一応作成しましたが、結果はボロボロでした。
https://blog.logicky.com/2019/02/21/142607 — blog.logicky.com
前回のコードは、テスト不十分だったので、とりあえず、実際に想定どおりに注文・約定・利確・損切等が行われるようになっているのかを確認するためのコードを追加しました。そして、動作確認・バグ修正しました。あとは、DQNにはクリッビングとかいうのが大事で、報酬の下限・上限を決める方がいいということだったので、-50〜50までにしました。あと、トレーニング中、テスト中に実際に選択しているアクションを全部表示させるようにしたりしました。あとは、中間層の数をめっちゃ増やしたり、EpsGreedyQPolicyを、LinearAnnealedPolicyに変えてみたりしました。
env.py
import mathimport gymimport numpy as npimport gym.spacesimport jsonimport timeimport osimport sysfrom random import randint
class BfEnv(gym.Env): def __init__(self): super(BfEnv, self).__init__() self.action_space = gym.spaces.Discrete(3) self.observation_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(300, 7), dtype=np.float32) self.reward_range = [-50., 50.] self.executions = self._readJsonFile() self._reset()
def _readJsonFile(self): with open('executions2.json') as f: return np.array(json.load(f))
def _resetIdx(self): max = self.executions.shape[0] - 900 + 1 # 300は5分のこと。5分分回して評価する min = 300 # 5分前のデータをobservationとして使う self.idx = randint(min, max) self.startIdx = self.idx self.endIdx = self.idx + 900 - 1
def _printResetState(self): print('startIdx: ', self.startIdx, 'endIdx: ', self.endIdx)
def _printState(self, reward): print('nowIdx: ', self.idx, 'reward: ', reward, 'done: ', self.done)
def _nextIdx(self): self.idx += 5
def _reset(self): self._resetIdx() self.done = False self.positions = [] self.orders = [] self.actions = [] self.rewards = [] self.totalProfit = 0 self._observe() # self._printResetState() return self.observation
def _observe(self): start = self.idx - 300 executions = self.executions[start:self.idx] self.observation = np.array(executions)
def _printStateDetail(self, action): time.sleep(1) os.system('clear') print('idx: ', self.idx) if action == 0: actionName = 'HOLD' if action == 1: actionName = 'BUY' if action == 2: actionName = 'SELL' print('action: ', actionName) nextExec = self.executions[self.idx + 1] print('--------------------------------') print('start: ', nextExec[0], 'end: ', nextExec[1]) print('min: ', nextExec[2], 'max: ', nextExec[3]) print('--------------------------------') print('orders', len(self.orders)) print('--------------------------------') for order in self.orders: print(order[0], order[1], order[2]) print('--------------------------------') print('positions', len(self.positions)) print('--------------------------------') for position in self.positions: print(position[0], position[1], position[2])
def _step(self, action): # self._printStateDetail(action) # for debug if action == 0: # hold pass elif action == 1: # buy self.orders.append([self.idx, 'BUY', self.executions[self.idx - 1][2]]) elif action == 2: # sell self.orders.append([self.idx, 'SELL', self.executions[self.idx - 1][3]]) # elif action == 3: # close # self._position_all_close()
self.actions.append(action) self._nextIdx() self._checkOrderTimeLimit() reward = self._checkPosition() if action == 0 and reward == 0: reward -= 1 self.rewards.append(reward) self.done = self.idx >= self.endIdx self._observe() # self._printState(reward) return self.observation, reward, self.done, {}
def _checkOrderTimeLimit(self): self.orders = [order for order in self.orders if self.idx < order[0] + 59]
def _checkPosition(self): executed = [] noExecuted = [] # 注文が約定するかチェック for order in self.orders: flag = False for exe in self.executions[self.idx - 5: self.idx]: if exe[2] <= order[2] <= exe[3]: # print('約定したで', exe[2], '<=', order[2], '<=', exe[3]) executed.append(order) flag = True break if not flag: noExecuted.append(order) self.orders = noExecuted
reward = 0 for exe in executed: isPosi = len(self.positions) > 0 if isPosi: side = self.positions[0][1] if exe[1] == side: self.positions.append(exe) # ポジ持ちすぎチェック if len(self.positions) > 5: # print('持ちすぎやで') reward += self._lossCut() else: # ポジ解除処理 reward += self._position_close(exe) else: self.positions.append(exe) # print('--------------------------------') # print('REWARD: ', reward) # print('--------------------------------') return reward
def _position_all_close(self): pass
def _position_close(self, exe): posi = self.positions.pop(0) side = posi[1] price = posi[2] nowPrice = exe[2] profit = 0 if side == 'BUY': # print('BUY', nowPrice, price, nowPrice - price) profit = nowPrice - price else: # print('SELL', nowPrice, price, price - nowPrice) profit = price - nowPrice self.totalProfit += profit if profit >= 10: return 10 elif profit >= 0: return 5 else: return -5
def _lossCut(self): totalPrice = 0 totalSize = len(self.positions) side = self.positions[0][1] for posi in self.positions: totalPrice += posi[2] avePrice = math.floor(totalPrice / totalSize) if side == 'BUY': nowPrice = self.executions[self.idx][2] reward = nowPrice - avePrice else: nowPrice = self.executions[self.idx][3] reward = avePrice - nowPrice # reward -= math.floor(nowPrice * 0.05 / 100) #0.05% # print('--------------------------------') # print('LOSSCUT') # print('--------------------------------') # print('POSI: ', side, avePrice, totalSize, 'closePrice: ', nowPrice) # print('profit: ', reward, ' x ', totalSize, ' = ', reward * totalSize) self.positions = [] # time.sleep(15) profit = reward * totalSize self.totalProfit += profit #強制解除で利益がマイナスなら一律で-50のreward if profit > 0: return 0 else: return -50
def _render(self, mode='human', close=False): out = sys.stdout out.write(str(self.idx)) out.write('\n--- Actions ---\n') out.write(' '.join(str(num) for num in self.actions)) out.write('\n--- Rewards ---\n') out.write(' '.join(str(num) for num in self.rewards)) out.write('\n')
def _close(self): pass
def _seed(self, seed=None): passby.py
import gymfrom keras.layers import Dense, Activation, Flattenfrom keras.models import Sequentialfrom keras.optimizers import Adamfrom rl.agents.dqn import DQNAgentfrom rl.memory import SequentialMemoryfrom rl.policy import EpsGreedyQPolicy, LinearAnnealedPolicyimport bf
ENV_NAME = 'bf-v0'# ENV_NAME = 'CartPole-v0'env = gym.make(ENV_NAME)nb_actions = env.action_space.nprint(nb_actions)
model = Sequential()model.add(Flatten(input_shape=(1,) + env.observation_space.shape))model.add(Dense(625))model.add(Activation('relu'))model.add(Dense(625))model.add(Activation('relu'))model.add(Dense(625))model.add(Activation('relu'))model.add(Dense(nb_actions))model.add(Activation('linear'))print(model.summary())
memory = SequentialMemory(limit=300000, window_length=1)policy = LinearAnnealedPolicy(EpsGreedyQPolicy(), attr='eps', value_max=1.0, value_min=0.1, value_test=0.05, nb_steps=100000)dqn = DQNAgent( model=model, nb_actions=nb_actions, gamma=0.95, memory=memory, enable_double_dqn=False, enable_dueling_network=False, nb_steps_warmup=1, target_model_update=1e-2, policy=policy)dqn.compile(Adam(lr=1e-3), metrics=['mae'])dqn.fit(env, nb_steps=5000000, visualize=False, verbose=2)
print('TEST')dqn.test(env, nb_episodes=5, visualize=True)JSONファイルの中身
前回は、具体的な金額ではなく、始値と終値の差額や、最低・最高額の差額などを差分にしており、価格の絶対値は使わないようにしてました。今回は、試しに使ってみることにしました。まだうまくいったことがないため、全てにおいて適当です。
[[392107,392101,392084,392108,0.01,3.039,38],[392101,392079,392079,392101,0.05,3.045,76],[392078,392052,392052,392080,0.51,3.493,104],[392079,392078,392052,392093,5.939,0.66,45],[392078,392079,392062,392089,1.631,0.174,34],[392089,392078,392078,392091,0.23,0.389,32],[392083,392078,392078,392083,0,0.423,5],[392078,392076,392068,392083,0.27,0.7,13],[392076,392071,392071,392076,0.01,0.01,2],[392064,392060,392050,392067,0.016,0.8,21],[392056,392049,392049,392060,0.053,0.535,15],[392050,392068,392049,392068,0.4,0.41,24],[392054,392048,392048,392064,0.08,0.459,17],[392054,392048,392048,392054,0,0.027,3],[392061,392075,392061,392075,2.769,0.173,28],[392075,392077,392062,392078,0.54,0.06,28],[392078,392063,392063,392093,4.15,0.151,42],[392073,392077,392069,392077,0.691,0.41,36],[392077,392093,392072,392093,1.92,0.1,11],...]結果
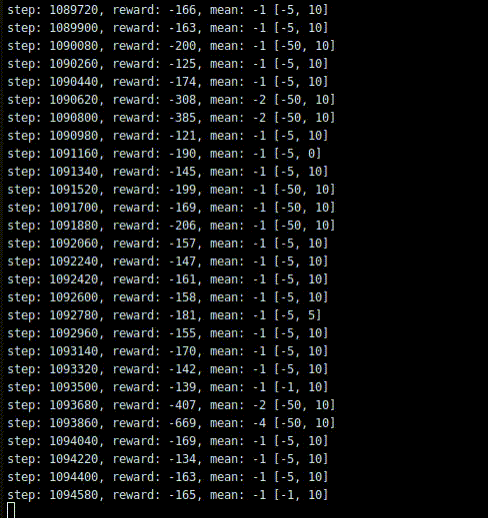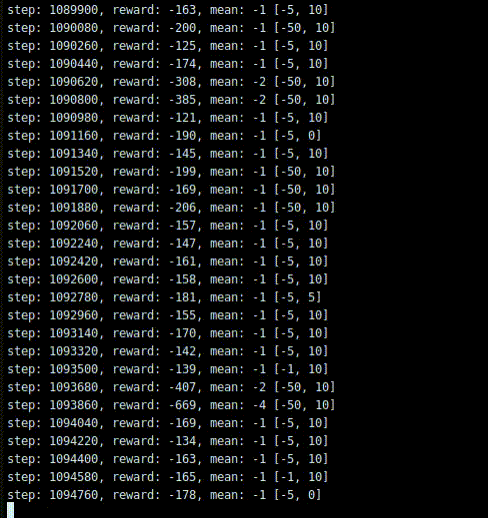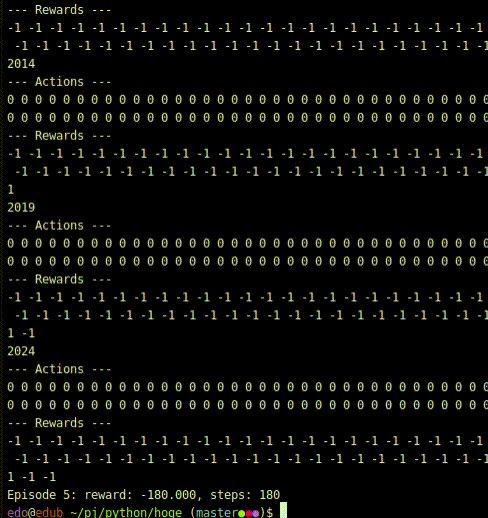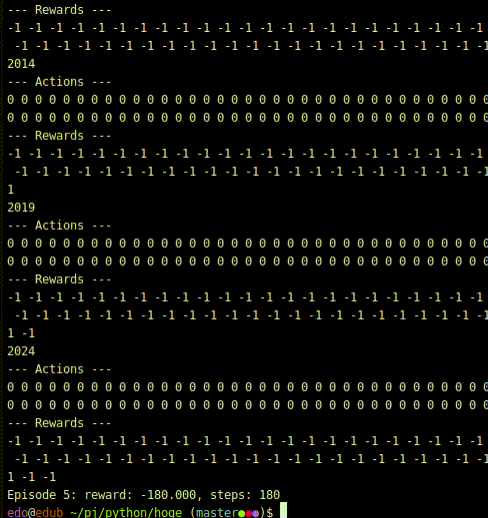
学習回数はかなり多く必要になるという記載が沢山あったので、一晩中学習させて、100万ステップまでやってみました。
結果は、何もしないことを学びました。