BTCFXの約定データで強化学習してみる (3)
前回、前々回と全然ダメでしたので、先人の知恵を探しておりました。基本的に下記のアリさんの過去のつぶやきを沢山拝見しました。ありがとうございますm(. .)m またアリさんがつぶやかれていた下記論文に関しても一応ぼんやりと眺めました。
sigfinいくつかみたけど、個人的には「高頻度注文情報の符号化と深層学習による短期株価予測」がよかったというか、やっていることがbotとだいだい同じで、入力の正規化どうするかずっと悩んでたり、分類問題にしてたりで、単に同意したいところが多かった。
— id:ultraist (@ultraistter) 2018年10月17日
前提
その上で、改めて考えた前提が下記になります。
予測に使うデータ
直近5分間の約定データ(サイド、価格、サイズ、約定時間)
データ数
データ数が合計で12,000になるように集約する。 0.05秒置きにBuy/Sell別々に集約したデータを5分間分、を想定してます。
サイド
成行注文のBuy or Sellです。BitflyerはNullの場合もあるっぽいので、それは無視を想定してます。
価格
価格は、カテゴライズされた相対価格です。とりあえず下記8カテゴリを想定しました。 マイナス側にも同様に8カテゴリあるので、全体で16カテゴリあります。
- 〜10
- 10 〜 30
- 30 〜 50
- 50 〜 100
- 100 〜 200
- 200 〜 500
- 500 〜 1000
- 1000 〜
どこからの相対価格にするのかというと、下記を想定しました。
- 基準価格: 直近5分間の最後のBuy価格とSell価格の真ん中の価格
サイズ
サイズは離散値にした方がいいのかよく分かりませんが、最大値は決められないし、とりあえず離散値にすることにしました。下記を想定しております。
- 〜 0.05
- 0.05 〜 0.1
- 0.1 〜 0.5
- 0.5 〜 1
- 1 〜 5
- 5 〜 10
- 10 〜 20
- 20 〜 40
- 40 〜 60
- 60 〜 100
- 100 〜
約定時間
これは、0.05秒間隔でcsvつくるので、配列の順番で相対的時間が分かる気がするので、データとしては削除することにしました。
アクション
下記を想定しております。
- 買う
- 売る
- 何もしない
報酬
- 利確成功: 1
- ポジ有効時間切れ: -1
売買ルール
- 10秒おきに、アクションを選択
- IN注文は、必ず約定できるものとし、約定価格は、上記の基準価格とする
- 利確幅: 50円
- ポジション有効時間: 60秒
今回目指すこと
前回までの反省
- 前回までは、適当に高難易度の結果を最初から求めていたので、どこをとってもめちゃくちゃであり、何がどう悪いのかすら分からなかった、というのがございます。
- 前回、前々回ともに、先に進みた過ぎてコードも適当すぎた。なおかつ学習結果も「何も取引しないことを学んだだけ」という結果でした。
今回の目標
- そこで今回は、報酬やアクションをできるだけシンプルにして、最重要課題である、超短期的値動き予測の精度のみを求めていきたいと思います。
- とりあえず、学習結果が、プラスになって、全てのアクションをしっかり使っている(一応売買する)状態を見たいです。
データ
今回はごちゃごちゃしたJSONからやっとシンプルなCSVになりました。CSV作成段階から、サイズをカテゴライズしております。Side, Size, Priceの順です。
データの形式
1,0,02,0,01,3,392299.02,0,01,0,02,3,392268.01,0,02,3,392270.01,0,02,1,392270.01,1,392299.02,4,392271.40000000011,3,392295.81データ生成コード
Numbaというのを使ってみたけど、引数と戻り値をしっかり規定通りの書き方で設定したりしないと有効にならないのかな??なんか全然速度が変わらなくて悲しい。
import pandas as pdimport datetime as dtfrom numba import jitimport csvimport time
@jit('int8(float64)')def _size_to_num(size): if size > 100: return 11 elif size > 60: return 10 elif size > 40: return 9 elif size > 20: return 8 elif size > 10: return 7 elif size > 5: return 6 elif size > 1: return 5 elif size > 0.5: return 4 elif size > 0.1: return 3 elif size > 0.05: return 2 elif size > 0: return 1 else: return 0
# @jitdef create_csv_data(end_time_str): df = pd.read_csv('raw_0213.csv') val = ['exec_date', 'side', 'size', 'price'] df = df[val] df['exec_date'] = pd.to_datetime(df['exec_date']) newData = [] end = dt.datetime.strptime(end_time_str, '%Y-%m-%dT%H:%M:%S.%f') start = end - dt.timedelta(milliseconds=50) buyTotalPrice, buyTotalSize, sellTotalPrice, sellTotalSize = [0, 0, 0, 0] df_rows = df.values for idx in range(df.shape[0]): row = df_rows[idx] exec_date, side, size, price = row if not size > 0: continue if not (start <= exec_date < end): # date = start.strftime('%H:%M:%S.%f')[:-3] buyAveragePrice = buyTotalPrice / buyTotalSize if buyTotalSize else 0 sellAveragePrice = sellTotalPrice / sellTotalSize if sellTotalSize else 0 newData.append([1, _size_to_num(buyTotalSize), buyAveragePrice]) newData.append([2, _size_to_num(sellTotalSize), sellAveragePrice]) buyTotalPrice = 0 buyTotalSize = 0 sellTotalPrice = 0 sellTotalSize = 0 end = start start = end - dt.timedelta(milliseconds=50) if side == 'BUY': buyTotalSize += size buyTotalPrice += price * size elif side == 'SELL': sellTotalSize += size sellTotalPrice += price * size return newData
print('start!')t = time.time()csvData = create_csv_data('2019-02-14T00:00:00.000')with open('bf_data/0213.csv', 'w') as f: writer = csv.writer(f) writer.writerows(csvData)print('finish!')print(time.time() - t)env.py
import gymimport numpy as npimport gym.spacesimport sysimport pandas as pdfrom random import randintimport copyfrom numba import jitimport time
def _read_csv(): df = pd.read_csv('bf_data/0213.csv') return df.values
@jit('int8(int64)')def _price_category(price_diff): price_abs = abs(price_diff) category = 0 if price_abs > 1000: category = 8 if price_abs > 500: category = 7 elif price_abs > 200: category = 6 elif price_abs > 100: category = 5 elif price_abs > 50: category = 4 elif price_abs > 30: category = 3 elif price_abs > 10: category = 2 elif price_abs > 0: category = 1 if price_diff < 0: category *= -1 return category
class BfEnv(gym.Env): def __init__(self): super(BfEnv, self).__init__() self.action_space = gym.spaces.Discrete(3) self.observation_space = gym.spaces.Box(low=-8, high=11, shape=(12000, 3), dtype=np.int16) self.reward_range = [-1, 1] self.executions = _read_csv()
self.one_sec_data_num = 40 # 1秒間のデータ数 self.train_data_num = self.one_sec_data_num * 60 * 5 # 学習に必要なデータ数 self.train_order_blank_num = self.one_sec_data_num * 3 # 学習から注文までのブランクを3秒間とする self.simulate_data_num = self.one_sec_data_num * 60 * 1 # シミュレーションに必要なデータ数 self.max_step_num = 200 # 1エポック当たりのステップ数 self.action_time_range = 10 # アクション発生の間隔(秒) self.rikaku_price_range = 50 # 利確値幅(円) self.idx = 0 self.done = False self.step_count = 0 self.base_price = 0 # 基準価格 self.actions = [] self.rewards = []
self.reset()
def _reset_idx(self): arr_len = self.executions.shape[0] actions_num = (self.one_sec_data_num * self.action_time_range + 1) * (self.max_step_num - 1) min_idx = actions_num + self.simulate_data_num + self.train_order_blank_num - 1 max_idx = arr_len - 1 - self.train_data_num self.idx = randint(min_idx, max_idx)
def _next_step(self): self.idx -= self.one_sec_data_num * self.action_time_range + 1 self._observe()
def reset(self): t = time.time() self._reset_idx() self.done = False self.step_count = 0 self.actions = [] self.rewards = [] self._observe() # print('reset: ', time.time() - t, ' sec') return self.observation
def _observe(self): t = time.time() train_data_start_idx = self.idx + 1 # start_idxの方が新しいデータ train_data_end_idx = train_data_start_idx + self.train_data_num - 1 self._base_price(train_data_start_idx) observation_temp = [] for idx in range(train_data_start_idx, train_data_end_idx + 1): price_category = 0 if self.executions[idx][2] > 0: price_diff = self.executions[idx][2] - self.base_price price_category = _price_category(price_diff) execution = copy.deepcopy(self.executions[idx]) execution[2] = price_category observation_temp.append(execution) self.observation = np.array(observation_temp) # print('_observe: ', time.time() - t, ' sec')
def _base_price(self, idx): buy_price, sell_price = [0, 0] while True: if buy_price > 0 and sell_price > 0: break if self.executions[idx][2] > 0: if self.executions[idx][0] == 1 and buy_price == 0: buy_price = self.executions[idx][2] elif self.executions[idx][0] == 2 and sell_price == 0: sell_price = self.executions[idx][2] idx += 1 self.base_price = int((sell_price - buy_price) / 2 + buy_price)
# action 0 = hold, 1 = buy, 2 = sell def step(self, action): t = time.time() self.step_count += 1 reward = 0 if action != 0: reward = self._simulate(action) # self.rewards.append(reward) self.actions.append(action) self._next_step() self.done = self.max_step_num <= self.step_count # print('step: ', time.time() - t, ' sec') return self.observation, reward, self.done, {}
def _simulate(self, side): t = time.time() posi_price = self.base_price rikaku_price = posi_price + self.rikaku_price_range if side == 2: rikaku_price = posi_price - self.rikaku_price_range end_idx = self.idx - self.train_order_blank_num start_idx = end_idx - self.simulate_data_num + 1 max_price = 0 min_price = 100000000 for idx in range(start_idx, end_idx + 1): if 0 < self.executions[idx][2] < min_price: min_price = self.executions[idx][2] elif self.executions[idx][2] > max_price: max_price = self.executions[idx][2] if min_price <= rikaku_price <= max_price: return 1 # print('_simulate: ', time.time() - t, ' sec') return -1
def render(self, mode='human', close=False): if self.step_count % 200 == 0: out = sys.stdout out.write(' '.join(str(num) for num in self.actions)) out.write('\n')
def _close(self): pass
def _seed(self, seed=None): passbf2,py
import gymfrom keras.layers import Dense, Activation, Flattenfrom keras.models import Sequentialfrom keras.optimizers import Adamfrom rl.agents.dqn import DQNAgentfrom rl.memory import SequentialMemoryfrom rl.policy import EpsGreedyQPolicy, LinearAnnealedPolicyimport bf2
ENV_NAME = 'bf-v2'env = gym.make(ENV_NAME)nb_actions = env.action_space.n
model = Sequential()model.add(Flatten(input_shape=(1,) + env.observation_space.shape))model.add(Dense(64))model.add(Activation('relu'))model.add(Dense(256))model.add(Activation('relu'))model.add(Dense(64))model.add(Activation('relu'))model.add(Dense(nb_actions))model.add(Activation('linear'))# print(model.summary())
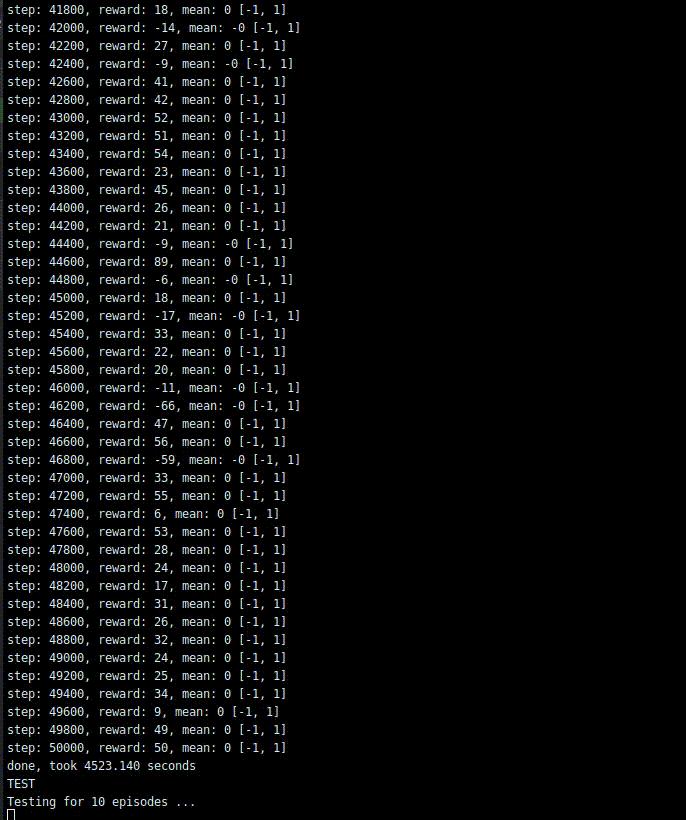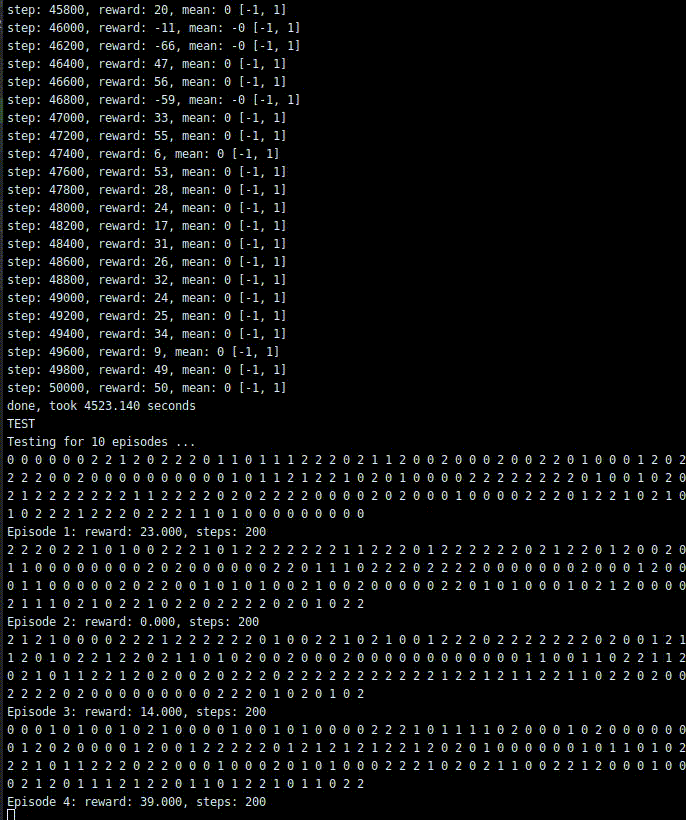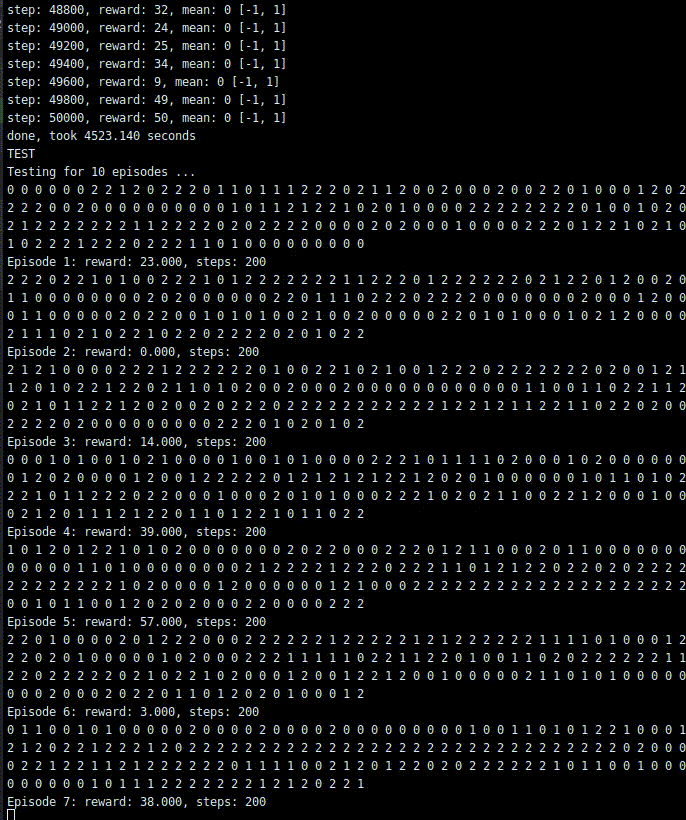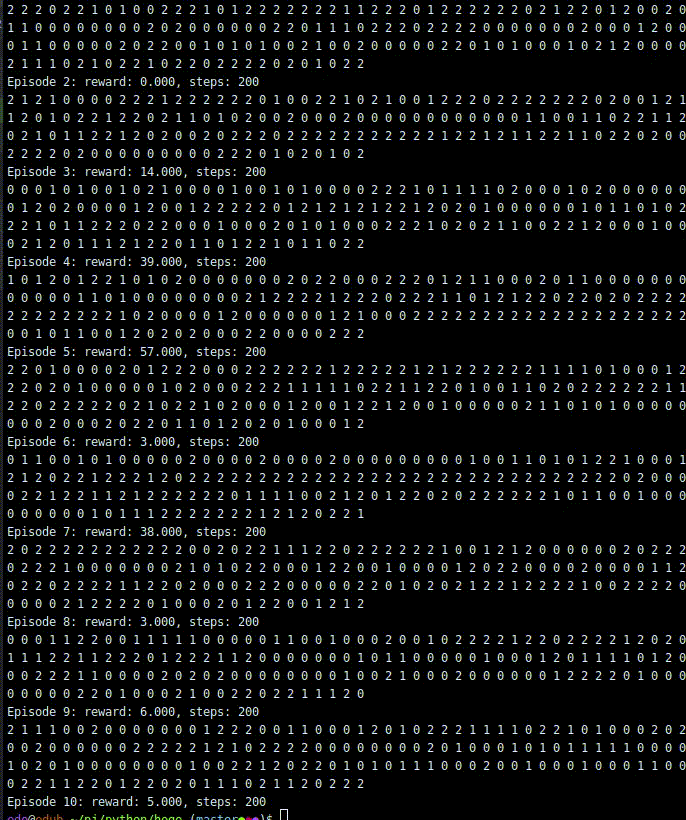
memory = SequentialMemory(limit=300000, window_length=1)policy = LinearAnnealedPolicy( EpsGreedyQPolicy(), attr='eps', value_max=1.0, value_min=0.1, value_test=0.05, nb_steps=2500)dqn = DQNAgent( model=model, nb_actions=nb_actions, gamma=0.99, memory=memory, enable_double_dqn=False, enable_dueling_network=False, nb_steps_warmup=100, target_model_update=1e-2, policy=policy)dqn.compile(Adam(lr=1e-3), metrics=['mae'])dqn.fit(env, nb_steps=50000, visualize=False, verbose=2)
print('TEST')dqn.test(env, nb_episodes=10, visualize=True)学習結果
一応取引をしてくれました。ただ、1step目と50000ステップ目でほぼrewardが変わってない気もします。